目录
一、匿名管道
1、介绍进程间通信
2、理解管道
3、管道通信
4、用户角度看匿名管道
5、内核角度看匿名管道
6、代码实现匿名管道
6.1 创建子进程
6.2 实现通信
7、匿名管道阻塞情况
8、匿名管道的读写原子性
二、命名管道
1、命名管道
1.1 命名管道通信
2、代码实现命名管道
结语
前言:
在Linux下有一种概念叫做管道,管道的作用是实现进程间通信功能,其本质是一个文件,该文件也被当成进程通信的缓冲区,即一个进程往缓冲区内写数据,另一个进程从缓冲区内读数据,这一过程称之为进程间通信。管道分为两种:匿名管道、命名管道,匿名管道只限于含亲缘关系的进程间通信,而命名管道可以让两个无亲缘关系的进程进行通信。
一、匿名管道
1、介绍进程间通信
进程间通信在Linux下是个很重要的概念,他允许两个以上的进程进行相互传递数据,在如今的实际生活中,早已离不开进程间通信,因为日常生活中的网上冲浪就是一种进程通信的行为,只不过通信的进程在不同的主机上,但是不论是不同主机的进程通信还是同一主机的进程通信的逻辑都相差不差,即进程间要看到相同的资源。
2、理解管道
管道就是一种在同一主机下的进程通信,他的作用就如同现实中的“管道”一样,只允许一边写数据一边读数据,因此单个管道是一种半双工的通信方式。在Linux下可以使用管道将两个以上的指令进行结合输出,操作指令如下:

管道的作用就是将前一个指令的输出结果写进管道,让后一个指令从管道中读取内容并执行。
管道示意图:
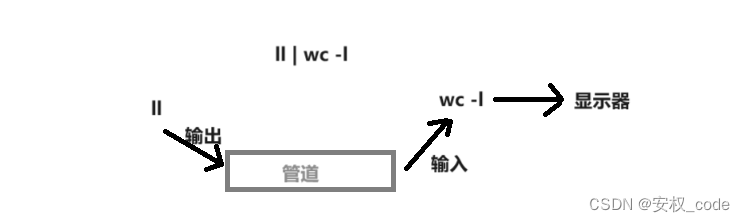
3、管道通信
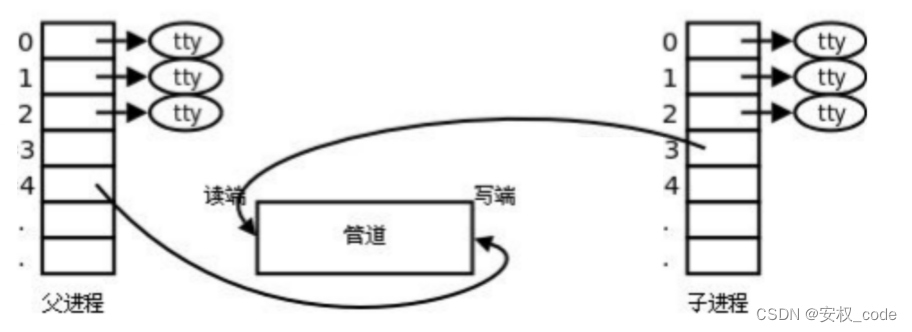
管道是进程通信中一种最古老的方式,因为指令就是进程,所以在上述例子中,ll进程和wc进程利用管道进行进程通信,只不过通信的过程让系统封装好了,因此在上层无法清晰的看到整个通信过程,但是能够明白管道的通信逻辑是让两个进程看到同一份资源,所以使用管道进行进程通信的具体结构图如下:

上图中父进程创建了一个子进程,并且子进程通过拷贝父进程的PCB,也会让子进程指向管道文件,此时就满足了两个进程看到同一份资源的条件(ps:0、1、2是默认打开的3个文件描述符,他们对应上层的三个文件流stdin、stdout、stderr)。
将带有亲缘进程间通信的管道称为匿名管道,值得注意的是:管道的原理就是在内存上开一个临时文件,而不是在磁盘上新建文件,所以当管道文件由系统自动识别并回收。
4、用户角度看匿名管道
匿名管道只适用于亲缘进程间通信,在用户层面上只关心进程文件描述符和管道文件的关系,具体使用匿名管道通信的步骤如下:
1、父进程在fork子进程前要先创建管道文件,并且以读、写方式打开管道文件,此时会返回两个文件描述符3、4。

2、父进程fork出子进程,因此子进程的3、4文件描述符也会指向同一个管道文件。

3、父进程关闭文件描述符3,子进程关闭文件描述符4(或者相反),这样做的原因是当下只有一个缓冲区存放通信的数据,若一个进程既能写又能读,则无法保证该进程读到的数据一定是对方发来的数据,因为有可能读到自己发送的数据。
此时就可以进行父进程向子进程发送数据的通信方式了。
5、内核角度看匿名管道
从内核角度看匿名管道通信,父进程创建管道文件时,会以读、写两种方式打开管道文件,因此在内核中一个管道文件是被打开了两次,可以理解为创建了两个struct file的结构体来管理一个管道文件。
具体示意图如下:

注意:上图父进程关闭文件描述符3,子进程关闭文件描述符4,所以当前管道文件的struct file的引用计数是2,只有关闭了父进程的文件描述符4和子进程的文件描述符3,系统才会回收管道文件。
6、代码实现匿名管道
系统已经为用户提供了实现匿名管道的接口,接口介绍如下:
#include <unistd.h>//pipe所需要的头文件
//传一个数组给到pipe,pipe调用成功时返回0,失败返回-1
//调用成功pipefd数组的第一个元素是读的下标,第二个元素是写的下标
int pipe(int pipefd[2]);
代码验证pipe接口:
#include<iostream>
#include<unistd.h>
#include <errno.h>
using namespace std;
int main()
{
int pipefd[2]={0};
int n = pipe(pipefd);
if(n == -1)
{
perror("pipe");
return -1;
}
cout<<pipefd[0]<<" "<<pipefd[1]<<endl;
return 0;
}运行结果:
![]()
从结果可以发现,pipe确实改变了数组pipefd元素的值,让该进程的3号文件描述符以读的方式打开管道文件,该进程的4号文件描述符以写的方式打开文件,说明底层已经完成了使用匿名管道通信的第一步,即下图:
6.1 创建子进程
有了上述的代码基础,就可以创建子进程并建立进程间通信的整体架构了,代码如下:
#include <iostream>
#include <unistd.h>
#include <errno.h>
using namespace std;
int main()
{
int pipefd[2] = {0};
int n = pipe(pipefd);
if (n == -1)
{
perror("pipe");
return -1;
}
// 下面实现的是子进程写,父进程读
pid_t id = fork();
if (id < 0)
return -2;
// chlid
if (id == 0)
{
close(pipefd[0]); // 关闭读,子进程只写
// 子进程的通信过程
cout << "子进程开始传输数据" << endl;
sleep(3);
close(pipefd[1]); // 通信完毕后关闭写端
exit(0);
}
// father
close(pipefd[1]); // 关闭写,父进程只读
// 父进程的通信过程
cout << "父进程开始读取数据" << endl;
sleep(3);
close(pipefd[0]); // 通信完毕后关闭读端
return 0;
}运行结果:

上述代码完成的是匿名管道通信的第二步、第三步:
6.2 实现通信
创建子进程并建立起进程通信的框架后,就可以进行父子进程通信了,所以需要在上述代码的通信过程中实现具体的通信,代码如下:
#include <iostream>
#include <unistd.h>
#include <errno.h>
#include <cstring>
using namespace std;
#define NUM 1024
// child
void Writer(int wfd)
{
string s = "你好父进程,我是子进程";
pid_t self = getpid();
int number = 0, time = 5;
char buffer[NUM];
while (time--)
{
sleep(1);
// 构建发送字符串
buffer[0] = 0;
snprintf(buffer, sizeof(buffer), "%s-%d-%d", s.c_str(), self, number++);
cout << buffer << endl;
// 发送/写入给父进程, system call
write(wfd, buffer, strlen(buffer));
}
cout<<"子进程数据发送完成"<<endl;
}
// father
void Reader(int rfd)
{
char buffer[NUM];
while (true)
{
buffer[0] = 0;
ssize_t n = read(rfd, buffer, sizeof(buffer) - 1); // 预留\0的位置
if (n > 0)
{
buffer[n] = 0; // 手动添加\0
cout << "父进程收到子进程的消息[" << getpid() << "]# " << buffer << endl;
}
else if (n == 0)
{
printf("father read file done!\n");
break;
}
else
break;
cout << endl;
}
}
int main()
{
int pipefd[2] = {0};
int n = pipe(pipefd);
if (n == -1)
{
perror("pipe");
return -1;
}
// 下面实现的是子进程写,父进程读
pid_t id = fork();
if (id < 0)
return -2;
// chlid
if (id == 0)
{
close(pipefd[0]); // 关闭读,子进程只写
// 子进程的通信过程
cout << "子进程开始传输数据" << endl;
Writer(pipefd[1]);
sleep(1);
cout << "子进程关闭写端" << endl;
close(pipefd[1]); // 通信完毕后关闭写端
exit(0);
}
// father
close(pipefd[1]); // 关闭写,父进程只读
// 父进程的通信过程
cout << "父进程开始读取数据" << endl;
Reader(pipefd[0]);
close(pipefd[0]); // 通信完毕后关闭读端
return 0;
}运行结果:

7、匿名管道阻塞情况
1、读写端正常,当管道为空,读端就会阻塞,比如在上述代码中让子进程停留在write函数之前,观察父进程read函数,测试结果如下:

发现父进程阻塞在read函数处,原因就是管道为空但读写端都未关闭,read函数读取不到任何数据会阻塞在此处。
2、读写端正常,当管道写满时,写端就会阻塞(因为管道也是有大小的),比如在上述代码中让父进程停留在read函数之前,这样就会让子进程一直往管道里写数据,最终导致管道被写满,导致write函数阻塞住,测试结果如下:
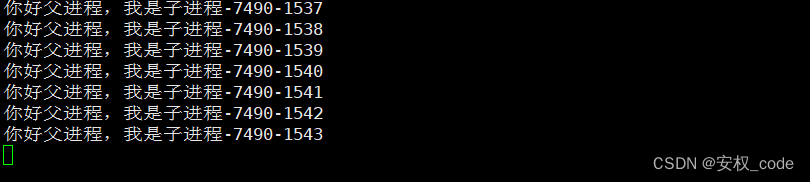
从结果看,子进程一直在写数据,但是父进程没有读取数据,最终导致子进程阻塞在write处。
3、读端正常,把写端的文件描述符关闭,在读端把管道内的数据读完后,下一次读取会导致read函数直接返回0,不会导致read阻塞,将上述代码的写端先关闭,读端不关闭,观察写端关闭后read函数的返回值,测试结果如下:

从结果看到,子进程写端关闭后,父进程的read函数就会返回0。
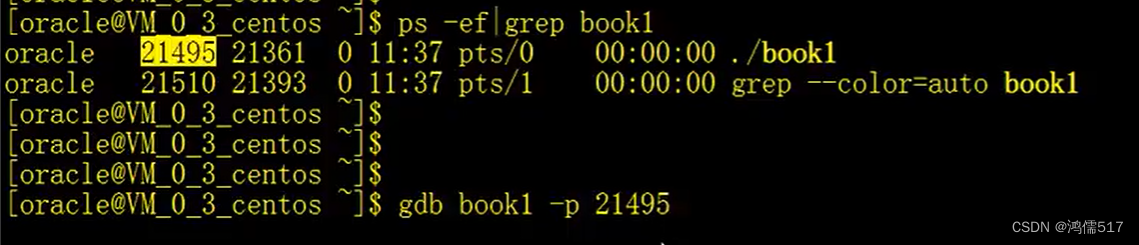
4、 写端正常,把读端的文件描述符关闭,此时操作系统会直接把整个写端进程以信号的方式终止,终止信号为13号,可以通过waitpid函数来获取子进程的终止信号,测试结果如下:

8、匿名管道的读写原子性
原子性即保证数据的完整性,比如写端写了hello world,则读端必须要等写端把整个hello world写完才能读,不能在写端写了一个hello时就去读。对于写入原子性,Linux规定当单次写入的数据小于等于PIPE_BUF(即管道的容量)则保证这一次的写入是原子性的,大于则不能保证原子性。对于读取原子性,可以理解为用户控制得好则读取就是原子性的,控制不好读取的大小则读取就不是原子性的。
二、命名管道
1、命名管道
上述的匿名管道的局限性在于只能作用于亲缘进程间通信,而现实生活中大多数进程间通信都不是亲缘关系,因此就引出另一个概念:命名管道,他允许两个以上的非亲缘进程进行通信,他是一种特殊的文件形式。因为管道文件是内存级别的,所以无论往里面写多少数据,管道文件的大小始终是0,原因就是管道文件的数据没有被写到磁盘中,仅仅在内存中就被消耗了。
在Linux指令中,通常用‘|’来表示匿名管道,同样命名管道也可以直接用指令创建出来,测试如下:

命名管道实现通信的逻辑就是让两个进程通过该“namepipe”命名管道文件进行通信,即发送端把数据写进该文件里,读取端从该文件里读数据,并且这两个进程可以是无亲缘关系的,因为他们只需要找到namepipe文件的路径即可完全通信。
1.1 命名管道通信
这里用两个窗口模拟两个进程,一个窗口给命名管道发送数据,另一个窗口从管道中读取数据,以此完成通信,测试结果如下:

从结果发现,依靠命名管道完成了两个进程的通信。
2、代码实现命名管道
和实现匿名管道逻辑一样,系统为上层提供了一个接口mkfifo来创建命名管道,指令介绍如下:
#include <sys/types.h>
#include <sys/stat.h>
int mkfifo(const char *pathname, mode_t mode);
//pathname表示创建命名管道的路径
//mode表示命名管道的权限
//mkfifo成功返回0,失败返回-1有了此接口,就可以实现简单的无亲缘进程间通信了,我们可以创建两个独立的主进程(发送方和接收方),然后通过mkfifo生成的命名管道进行通信。
发送方代码如下:
#include <iostream>
#include <sys/types.h>
#include <sys/stat.h>
#include <cstring>
#include <unistd.h>
#include <errno.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
using namespace std;
int main()
{
int fd = open("my_namepipe", O_WRONLY);
if (fd == -1)
{
perror("open");
return -1;
}
string line;
while (true)
{
cout<<"客户端发送的数据:";
cin>>line;
int n = write(fd,line.c_str(),strlen(line.c_str()));
if(n==-1)
{
perror("write");
return -1;
}
}
close(fd);
return 0;
}命名管道文件由接收方在通信前生成,接收方代码如下:
#include <iostream>
#include <sys/types.h>
#include <sys/stat.h>
#include <cstring>
#include <unistd.h>
#include <errno.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
using namespace std;
int main()
{
int mode = 0666;
int n = mkfifo("./my_namepipe", mode);
if (n == -1)
{
perror("mkfifo");
return -1;
}
int fd = open("my_namepipe", O_RDONLY);
if (fd == -1)
{
perror("open");
return -1;
}
char buff[1024];
while (true)
{
int n = read(fd, buff, sizeof(buff) - 1);
if (n > 0)
{
buff[n] = 0;
cout << "服务器接收到的数据:" << buff << endl;
}
}
close(fd);
if(unlink("my_namepipe")==-1)
{
perror("unlink");
return -1;
}
return 0;
}运行结果:

注意事项:读端、写端双方必须都打开了命名管道文件才会都往下执行,也就是说只要有一方没有打开命名管道文件,则另一方就会阻塞在open处。
结语
以上就是关于管道的讲解,管道分两种:匿名管道、命名管道,两者都可进行进程间通信,只不过匿名管道适用于亲缘进程,而命名管道可以使用非亲缘进程,并且系统提供这两个管道的接口给予用户使用,用户也可以在指令层面上使用他们,他们通信的本质都是让两个进程看到同一份资源,对该资源的读写就是通信的过程。
最后如果本文有遗漏或者有误的地方欢迎大家在评论区补充,谢谢大家!!








![[图解]企业应用架构模式2024新译本讲解21-数据映射器3](https://img-blog.csdnimg.cn/direct/99fc318023cd413b9abed365647a9df9.png)